논문 요약: 본 논문에서는 Explanation-Enhanced Knowledge Distillation 방법을 제안하며, 이를 통해 학생 모델이 단순히 교사 모델의 출력을 모방하는 것이 아니라, 교사 모델이 학습한 설명의 유사성까지 유지하도록 학습할 수 있음을 보여줌.
연구 배경
- Knowledge Distillation(KD)는 큰 교사 모델의 지식을 작은 학생 모델로 전달해서 경량 모델을 효과적으로 학습하는 기법이다.
- 하지만 기존 KD 방식에서는 학생 모델이 교사 모델과 유사한 예측 결과를 보일 수는 있어도, 학습 과정에서 동일한 의사결정 논리를 따르지 않을 가능성이 크다.
- 이런 문제는 모델의 신뢰성을 저하시키고, 모델이 정답을 맞히더라도 잘못된 이유로 결정할 가능성을 높인다. (wrong for the right reasons)
- 특히 모델의 해석 가능성이 중요한 분야에서는 단순한 성능 향상이 아니라, 모델이 정답을 도출하는 과정 자체가 의미있게 유지되는 것이 중요하다.
연구의 필요성
- 기존의 KD 방법은 학생 모델의 출력(Logit)만을 교사 모델과 유사하게 만들기 때문에, 학생 모델이 교사 모델과 동일한 학습 패턴을 유지한다는 보장이 없다.
- 학생 모델이 교사 모델과 다른 입력 특징을 사용할 경우에 성능이 급격하게 저하될 수 있다.
- 본 연구에서는 교사 모델의 단순한 예측값 전달이 아니라, 교사 모델의 설명 방식(ex. Grad-CAM)을 학생 모델이 직접 학습하도록 유도하는 방법을 제안한다.
- 결과적으로 옳은 이유로 옳은 결정을 할 수 있는 모델을 학습시킨다. (right for the right reasons)
연구 방법론
💡 Train
- 학생 모델은 교사 모델의 logit 분포와 설명(explanation)을 동시에 최적화하여 학습한다.
- 추가로, 실험과정에서는 교사 모델이 평가하는데 소요되는 계산 비용을 줄이기 위해 고정된 교사 모델(fixed teacher)을 사용하는 방법 사용한다.
💡 Evaluation
-
e2KD는 Faithful KD를 달성하기 위해 다음의 세 가지 요건을 만족해야 한다.
1) High Agreement with Teacher (교사와의 높은 일치도)
- 일치도는 입력데이터 𝑥에 대해 교사와 학생이 동일한 예측을 얼마나 자주 내놓는 지로 정의됨.
- Faithful KD에서는 학생 모델이 주어진 샘플에 대해 교사 모델과 동일한 방식으로 분류할 수 있도록, 즉 일치도가 높도록 보장해야 함.
2) Learning the ‘Right’ Features (‘올바른’ 특징 학습)
- 모델이 높은 정확도를 달성했더라도, 올바른 이유로 정답을 맞힌 것이 아닐 수 있음.
- 예를 들어, 이러한 경우에 human annotation같은 방법을 사용해서 올바른 특징을 사용하도록 유도하면 모델의 일반화 성능이 향상될 수 있음.
- faithful distillation은 학생 모델도 교사 모델처럼 올바른 특징을 사용할 수 있도록 보장해야 함.
3) Maintaining Interpretability (해석 가능성 유지)
- 교사 모델은 특정 훈련 패러다임이나 모델 아키텍쳐에 의해 explanation에서 바람직한 속성을 나타내도록 훈련될 수 있음.
- 이러한 속성이 학생 모델로 전달되는지 평가하기 위해 두 가지 설정을 제안함.
- 첫째, 학생 모델의 설명이 교사 모델이 학습한 속성을 얼마나 잘 반영하는지 평가. 특정 클래스에 대한 입력 특징을 얼마나 잘 localize하는지(위치를 잘 찾아내는지) 평가.
- 둘째, 학습되지 않은, 즉 모델 아키텍쳐 내에 내제된 prior 특성도 전이할 수 있는지 평가.
연구 결과 및 해석
4.1 e2KD Improves Learning from Limited Data
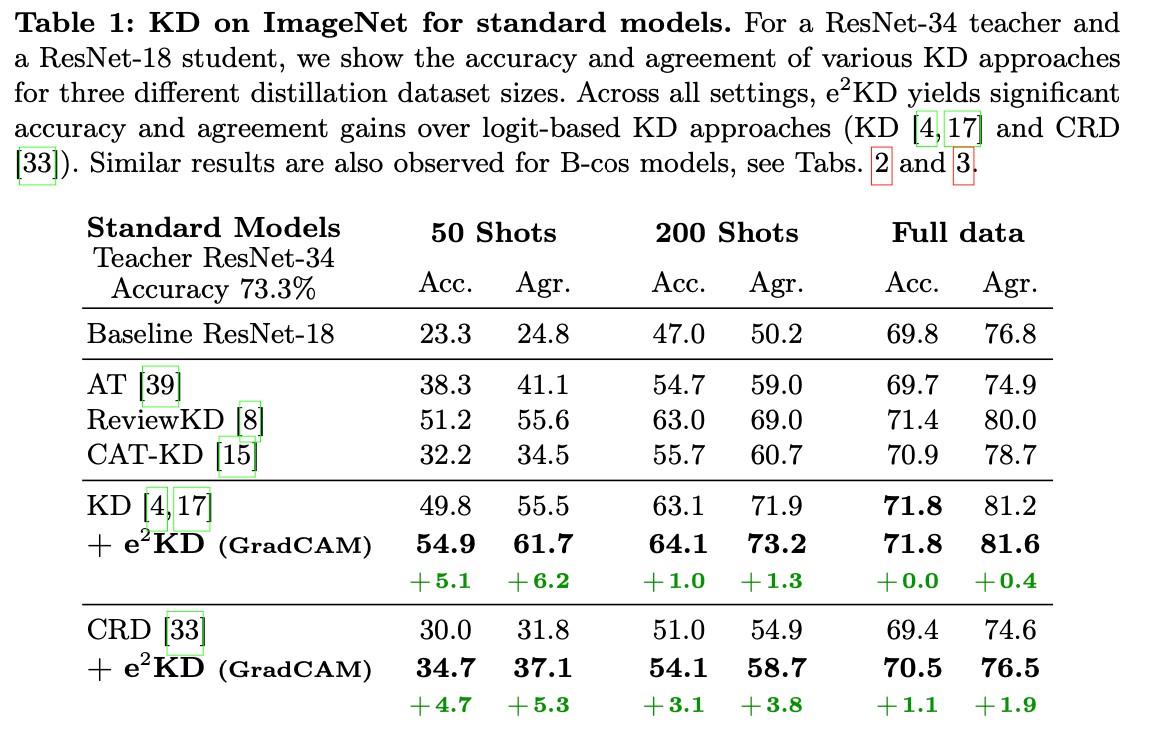
- ResNet-34 교사 모델과 ResNet-18 학생 모델로 다양한 KD 접근법의 정확도와 일치도를 세 가지 distill 데이터셋 크기에서 비교
- Explanation method: GradCAM
- 기존의 로그 기반 KD보다 e2KD가 더 높은 정확도(accuracy)와 일치도(agreement)를 보임.
- 데이터가 적을수록 e2KD의 성능향상 정도가 큼.
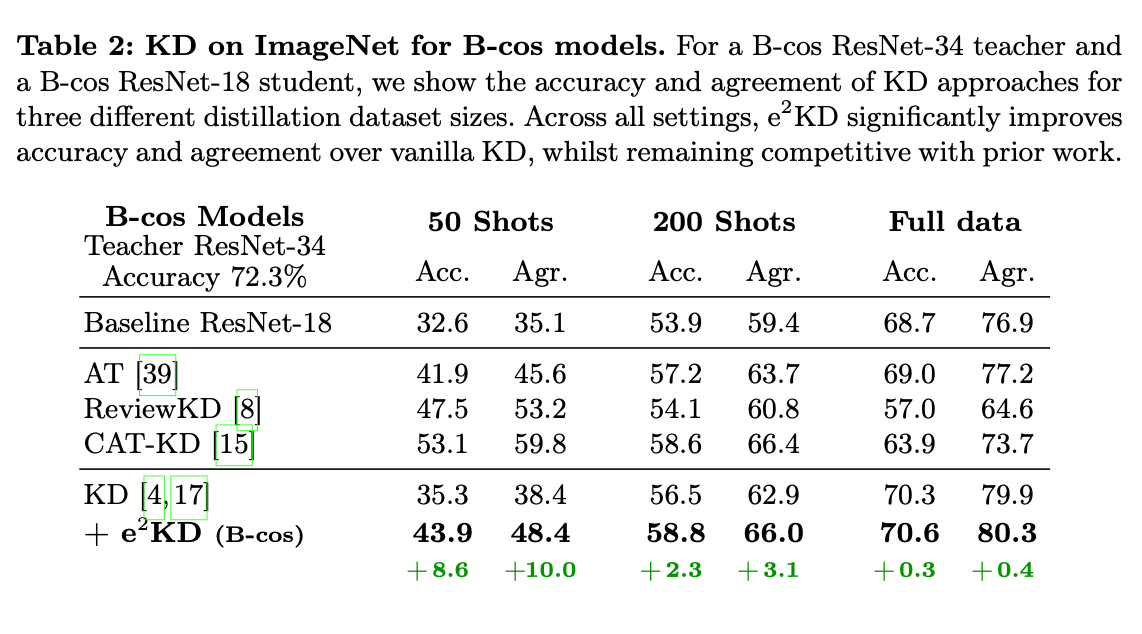
- Explanation method가 B-cos모델일 때도 e2KD가 기존 KD 방법보다 우수한 성능을 보임.
4.2 e2KD Improves Learning the ‘Right’ Features

- 학생 모델이 교사 모델과 동일한 input feature를 사용하는지 평가하기 위해 Waterbirds-100 데이터셋을 사용함.
- Waterbirds-100 데이터셋은 땅새와 물새를 분류하는 이진 분류 작업에 사용되는데, train할 때의 데이터는 새의 배경과 새의 class가 높은 상관관계를 가지도록 구성되어 있음.
- 교사 모델로 새의 특징에 집중하고 배경을 무시하도록 유도된 사전 학습된 ResNet-50모델을 사용
- 다양한 아키텍쳐를 학생 모델로 사용하여 아키텍쳐의 독립성을 검증
- 700epoch, mixup, 5x training 세 가지 조건에 대해 실험 진행함.
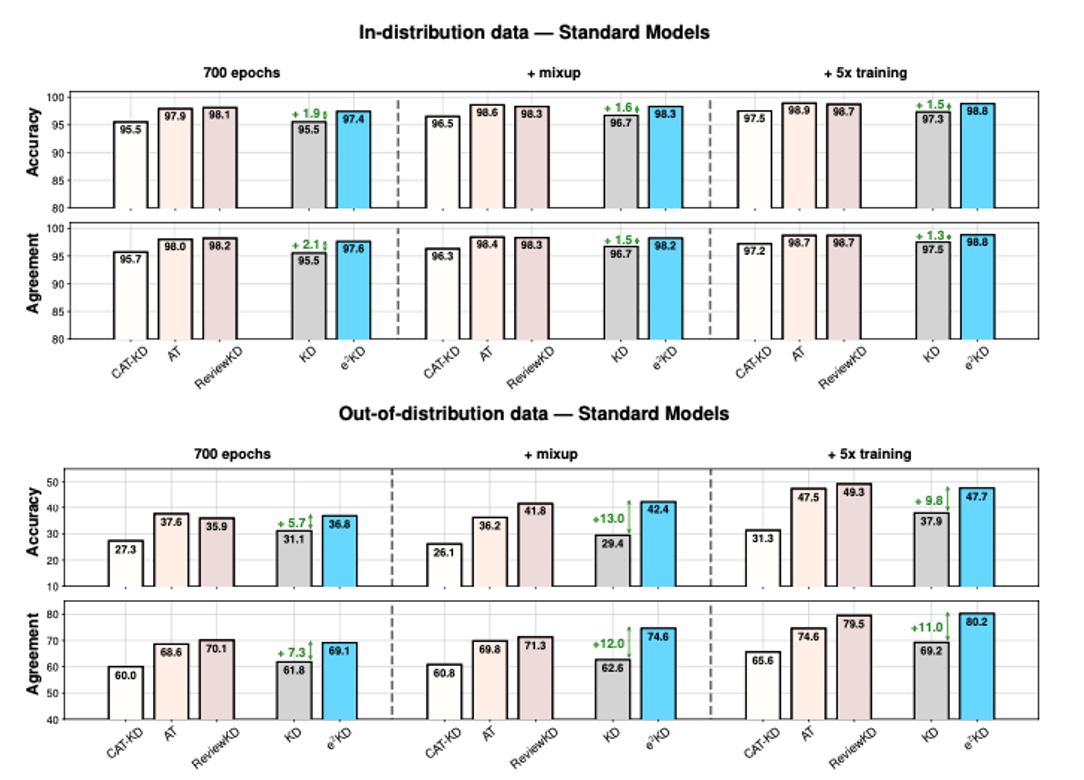
- (위) 모델이 훈련에 사용한 데이터 분포와 동일하거나 유사한 분포에서 생성된 데이터에서의 성능
- (아래) 훈련에 사용된 데이터 분포와 다른 분포에서 나온 데이터에서의 성능
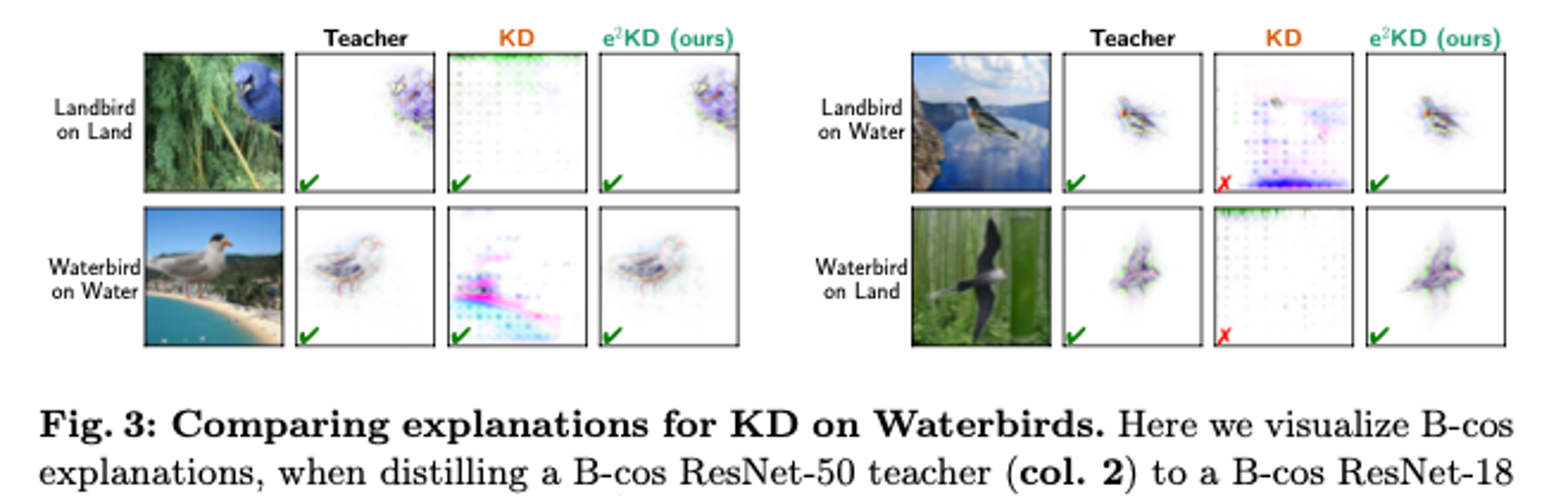
- B-cos 설명을 시각화하여 B-cos ResNet-50 교사모델로부터 B-cos ResNet-18학생 모델에 KD와 e2KD를 사용해 증류한 결과를 보여줌.
- 내분포 데이터(땅위의 땅새, 물위의 물새)에서는 모델의 초점(전경/배경)이 예측에 영향을 미치지 않아 올바르게 예측 하지만 외분포 데이터(땅위의 물새, 물위의 땅새)에서는 분포가 바뀐 상황이기 때문에 KD에서는 잘못된 예측을 하게 되지만, e2KD에서는 올바른 예측을 한다는 것을 알 수 있음.
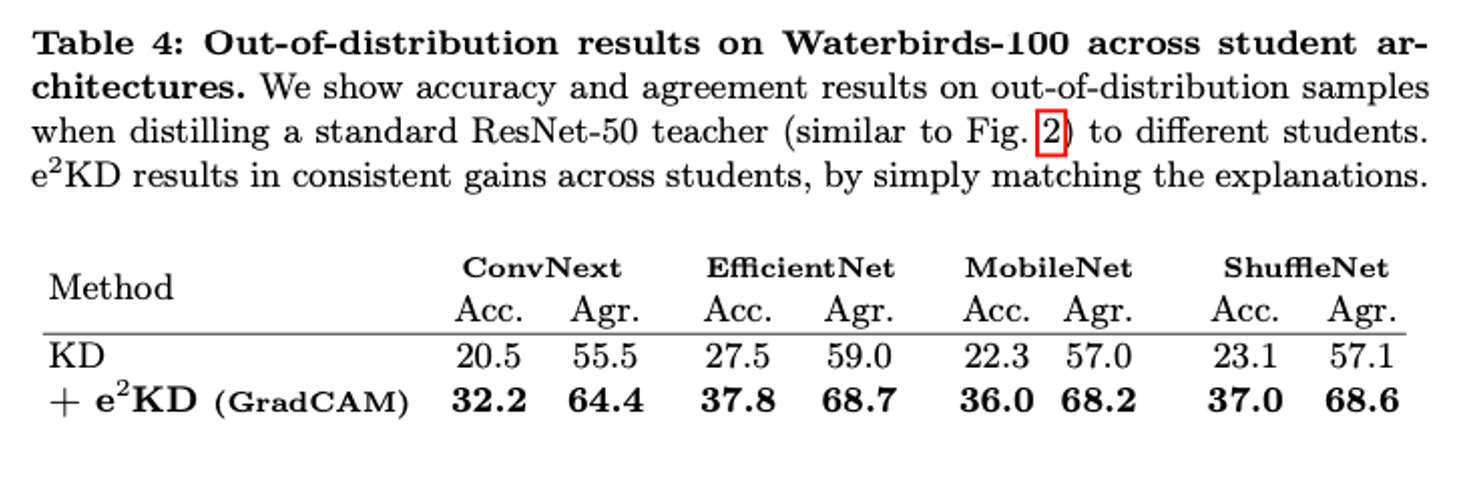
- 서로 다른 종류의 학생 모델에 증류할 때, 학습할 때 사용한 데이터셋과 다른 분포의 데이터셋에 대해서도 e2KD는 성능을 일관되게 향상시킴.
4.3 e2KD Improves the Student’s Interpretability
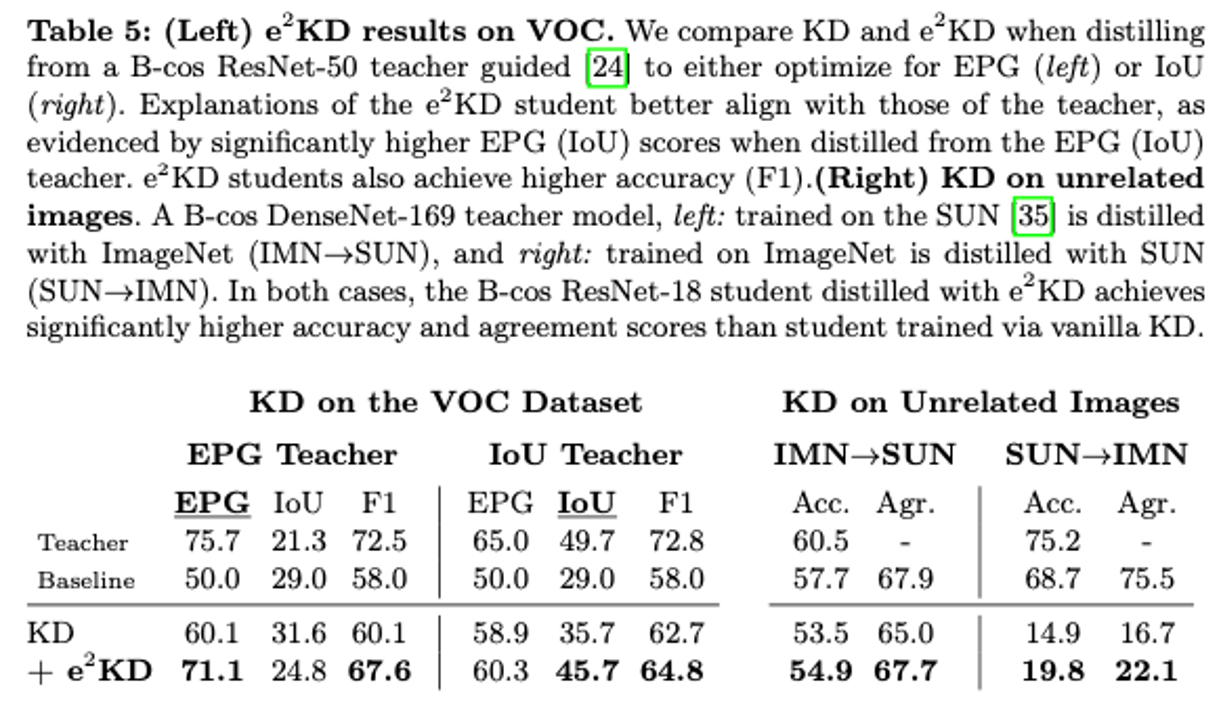
-
왼쪽 표: e2KD로 학습된 학생 모델은 EPG 교사로부터 증류된 경우 EPG 점수가, IoU교사로부터 증류된 경우 IoU 점수가 크게 높았음. ⇒ e2KD가 교사 모델의 해석적 특징을 효과적으로 전이함.
-
오른쪽 표: B-cos DenseNet-169 교사 모델을 SUN 데이터셋에서 학습한 후 ImageNet 데이터로 증류하거나, 반대로 ImageNet에서 학습한 후 SUN 데이터로 증류한 경우를 비교
두 경우 모두 e2KD를 사용한 학생 모델이 그렇지 않은 모델에 비해 높은 성능을 보임
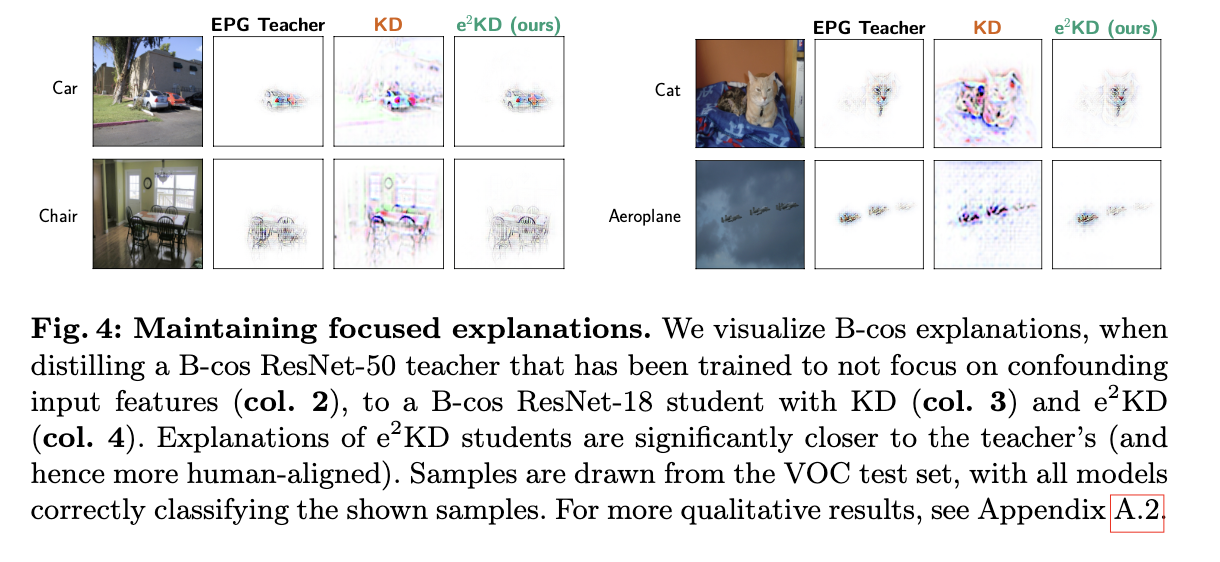
- e2KD 학생 모델의 설명이 교사 모델의 설명에 훨씬 더 가까움.
4.4 e2KD with Frozen Explanations
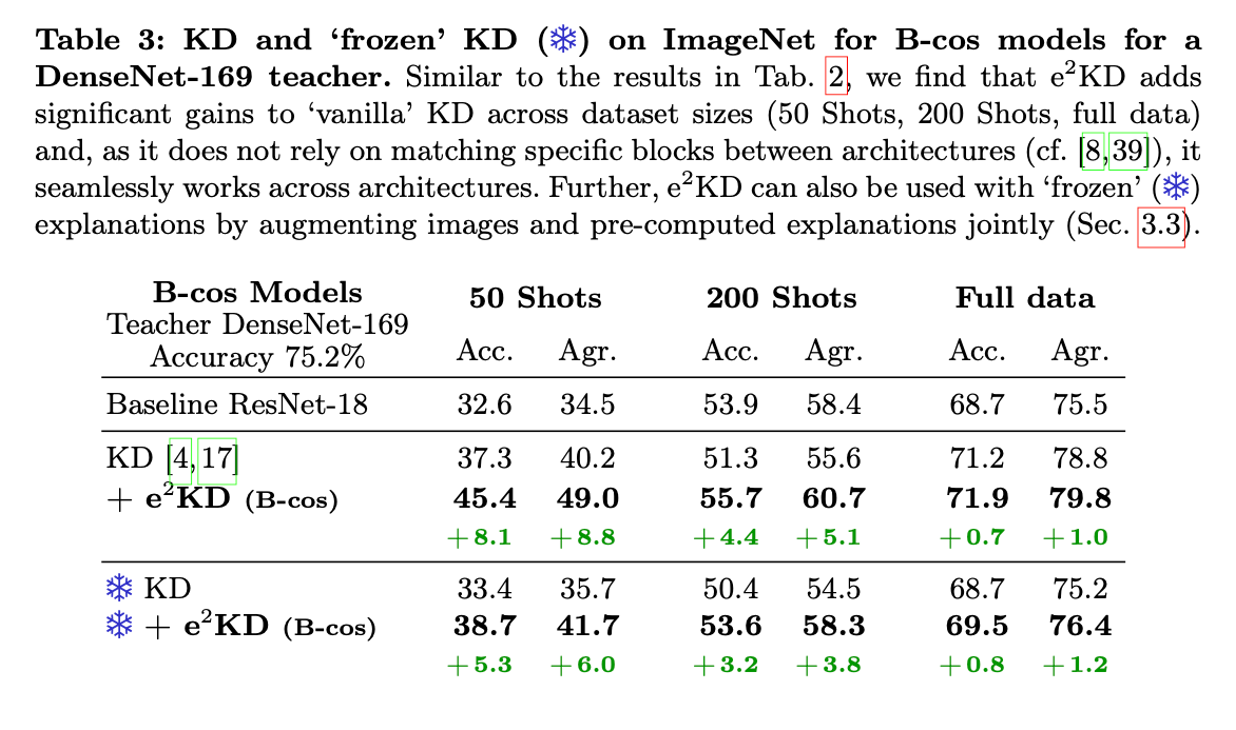
- frozen 설명을 사용하는 e2KD는 정확도와 일치도에서 KD보다 더 나은 성능을 보임. 50개의 shot에서도 정확도 33.4에서 38.7로 향상됨.
- frozen하지 않을때의 vanila KD에 비해서도 frozen한 상황에서 e2KD적용했을 때가 더 성능이 좋음.
결론
- 교사와 학생 간 설명 유사성을 명시적으로 최적화하여 KD의 faithfulness를 높이는 간단한 접근법 제안하고 다양한 환경에서 교사 모델의 특징을 효과적으로 증류할 수 있음을 입증함.
- e2KD는 학생 모델이 기본 KD보다 경쟁력있고, 더 높은 accuracy와 agreement를 달성하도록 하고 올바른 이유로 올바른 정답을 학습할 수 있도록 하며,교사 모델과 유사한 설명을 학습할 수 있도록 함.
- 추가로, 제한된 데이터, 근사적인 설명, 다양한 모델 아키텍쳐 환경에서도 강력한 성능을 보임.
✅ 결론적으로, e2KD는 단순하면서도 유연한 KD 보완 방법으로, 교사의 특성을 더 충실하게 증류하면서도 좋은 성능을 유지할 수 있도록 하는 KD 방법임.
Note: 나도 이 논문을 리뷰하고 나서 내 연구 주제를 생각하게 되었는데, 나중에 이에 대해서도 포스트 해보겠다!! “✍ʕ•ᴥ•oʔ