논문 요약: 본 논문에서는 LiDAR 기반 탐지기의 지식을 단일 카메라(단안) 기반 탐지기로 효과적으로 전달하는 새로운 지식 증류 방법을 제안함.
연구 배경
- 3D 객체 탐지는 증강 현실, 로봇 공학, 자율주행 등 다양한 분야에서 핵심 기술로 활용되며, 단안 카메라 기반 탐지는 저비용·고해상도 데이터 획득이 가능하여 주목받고 있음.
- 그러나 단안 카메라 기반 3D 탐지는 LiDAR 기반 탐지보다 3D 정보가 부족하여 성능 차이가 큼, 특히 깊이 정보가 부족하여 정확한 탐지가 어려움.
- 기존 연구에서는 Pseudo-LiDAR 기법을 활용해 단안 이미지를 3D 점군으로 변환하는 방식이 등장했으나, 여전히 LiDAR 데이터의 고유한 정보를 충분히 활용하지 못하는 문제가 있음.
연구의 필요성
- 기존의 Pseudo-LiDAR 방식은 단순히 depth map을 생성하는 방식에 그쳐, LiDAR 데이터의 고차원 특징(feature) 정보를 충분히 학습하지 못함.
- 또한 기존 방법들은 비효율적인 학습 전략을 사용하여 모델 최적화가 어려웠음.
- 본 연구에서는 LiDAR 탐지기의 정보를 단안 탐지기에 직접적으로 transfer하는 Cross-Modality Knowledge Distillation(CMKD) 기법을 제안하여, LiDAR 기반 탐지기의 특징과 응답 정보를 단안 탐지기에 효율적으로 학습시킴.
- 라벨링되지 않은 대규모 데이터를 활용한 반지도 학습 기법을 적용하여 라벨링 비용을 줄이면서 성능을 향상시킴.
연구 방법론
3.1 Framework Overview
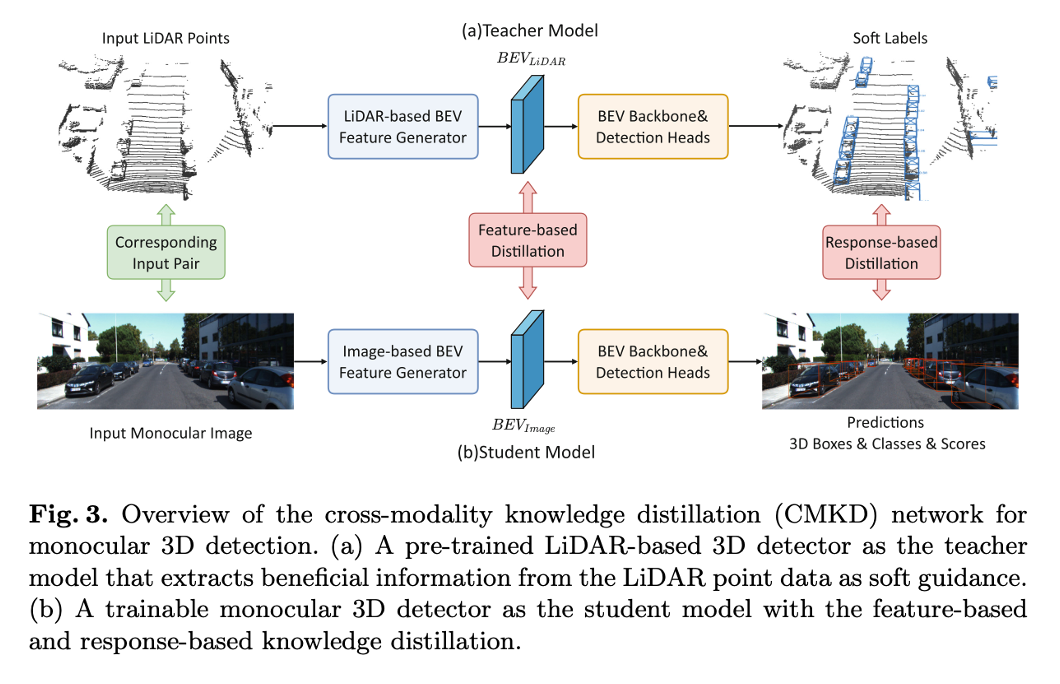
💡 Training
- monocular image와 해당하는 LiDAR 포인트를 입력 쌍으로 사용
- Teacher 모델: 사전 학습된 Teacher 모델은 LiDAR 포인트를 입력으로 받아 BEV feature map를 생성함. BEV feature map은 LiDAR 포인트에서 정확한 3D information을 계승하며, feature guidance로 사용됨. 또한, Teacher 모델은 3D 바운딩박스, 객체 클래스, confidence score를 포함한 예측 결과를 response guide로 제공함.
- Student 모델: 학습 가능한 student 모델은 monocular image로부터 BEV feature map과 3D 객체 탐지 결과를 생성할 수 있도록 학습되며, 유용한 지식을 전이받기 위해 Teacher 모델이 제공하는 feature level과 response level의 soft guidance를 활용함.
💡 Inference
- Inference 단계에서는 student 모델만 사용해서 monocular image를 입력으로 받아 3D 객체 탐지를 수행함.
3.2 BEV Feature Learning
(a) LiDAR-Based Branch
- LiDAR-based teacher model: SECOND 1) 입력된 LiDAR 포인트를 3D voxel로 분할하고, 이를 voxel backbone에 전달하여 voxel feature 추출 2) voxel feature를 높이 차원 (Z)으로 stack하여 LiDAR BEV feature map으로 변환 3) Teacher 모델의 학습 단계에서는 원래의 one-hot label 대신, Quality Focal Loss를 사용해서 IoU를 연속적인 품질 Label로 활용함. 신뢰 점수를 IoU 기반으로 예측하도록 학습
(b) Image-based Branch
- Image-based Student model: CaDDN 1) 입력된 이미지 I 에서 Image Backbone(ex. ResNet)을 사용해 image feature를 추출 2) depth distribution estimation network(ex. DeepLabV3)를 사용해 픽셀 단위의 depth distribution 예측 3) image feature와 depth distribution을 결합하여 frustum grid 𝐺를 생성 4) frustum volume을 calibration 매개변수로 보간하여 LiDAR 좌표의 직육면체 volume으로 변환 5) voxel feature를 축소하고, 채널 압축 네트워크를 통해 최종 image bev feature map 생성
3.3 Domain Adaptation via Self-calibration
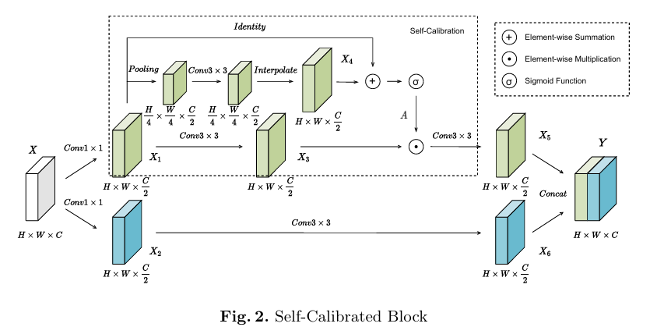
- LiDAR BEV feature와 Image BEV feature는 서로 다른 입력 모달리티와 백본을 기반으로 생성되기 때문에, 공간적 및 채널적 feature 분포에서 차이를 보임.
- 둘의 차이를 줄이고, 동시에 Image BEV Feature를 향상시키기 위해 domain adaptation (DA) 모듈을 도입함.
- 구체적으로, Image BEV Feature 뒤에 Self-Calibrated Block 5개를 stack하여 공간적 및 채널적 변환을 적용함.
3.4 Feature-Based Knowledge Distillation
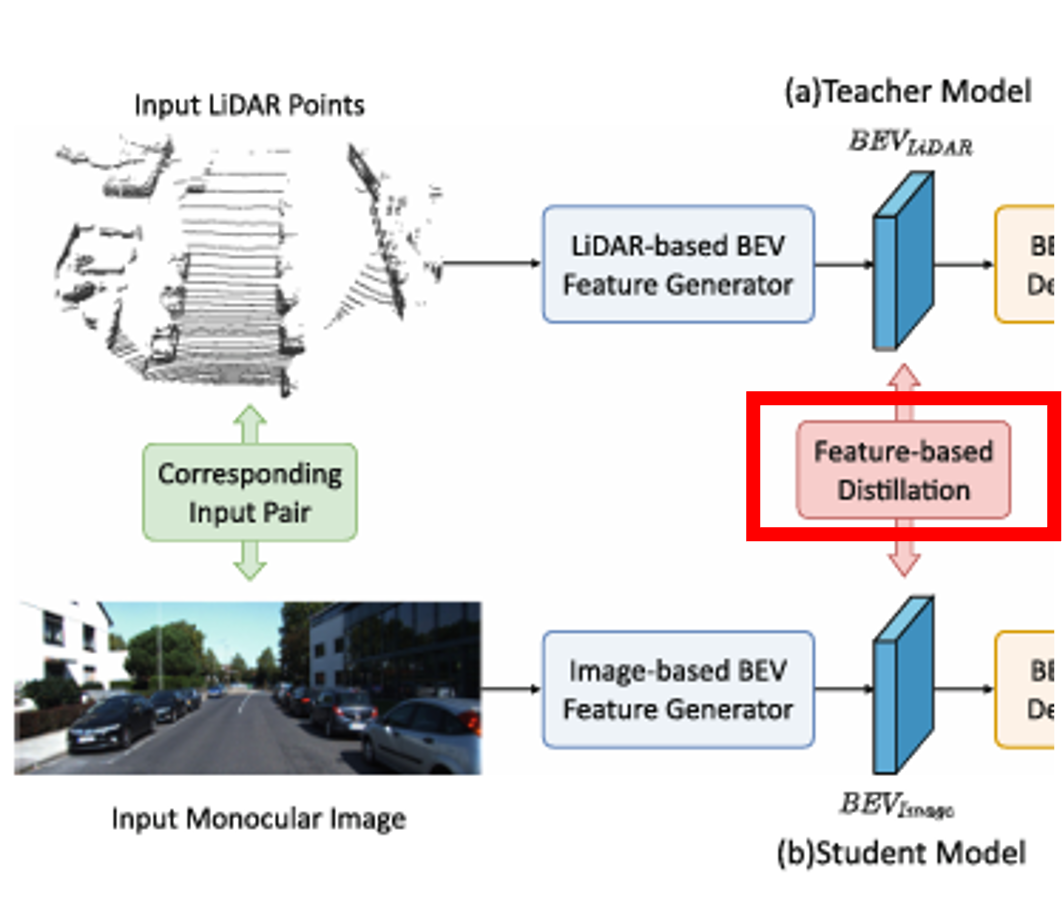
- LiDAR BEV feature를 Image BEV feature의 중간 고차원의 feature distillation guidance로 사용함.
- feature distillation loss는 MSE를 사용하여 계산함.
 $BEV_{Image}$: 이미지 기반 BEV feature, 깊이 정보에 의존해서 구성한 포인트 클라우드이기 때문에, 객체 윤곽이 뚜렷하지 않음.
$BEV_{Image}$: 이미지 기반 BEV feature, 깊이 정보에 의존해서 구성한 포인트 클라우드이기 때문에, 객체 윤곽이 뚜렷하지 않음.
- $L_{feat}$: feature distillation loss를 적용해서 LiDAR BEV feature에서 패턴을 학습하여 객체 윤곽이 일부 강조됨.
- $𝐷𝐴$: Domain adaptation을 통해 이미지 BEV feature가 LiDAR BEV feature와 더 유사해지게됨. $BEV_{LiDAR}$: LiDAR 기반 BEV feature, 정확한 3D 정보를 포함함.
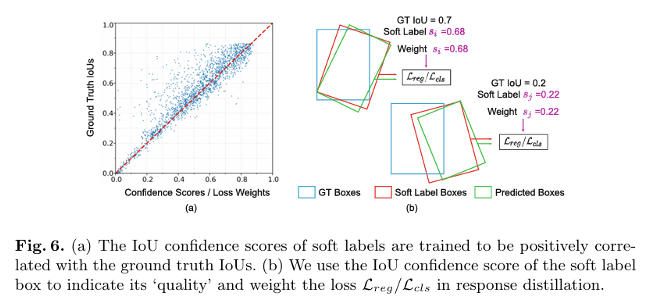
3.5 Response-Based Knowledge Distillation
- teacher 모델의 예측 결과 형태: soft label
- teacher 모델의 예측 결과를 student 모델의 response guidance로 활용
- Quality-Aware Distillation:

3.6 Loss Function

3.7 Extension: Distilling Unlabeled Data
- 기존의 단일 카메라 기반 3D 탐지 방법 (ex. Pseudo-LiDAR)들은 라벨 없는 데이터를 주로 깊이 정보를 학습하는 데만 사용함.
-
CMKD에서는 라벨 없는 데이터를 단순히 깊이 학습에만 사용하는 것이 아니라, 전체 네트워크를 최적화하는데 활용함. 1) Teacher 모델이 라벨이 있는 소수의 데이터를 사용해 먼저 학습 2) 이후 Teacher 모델이 라벨 없는 데이터에서 유용한 정보(soft guidance)를 추출 3) Teacher의 soft guidance를 바탕으로 라벨 없는 데이터를 활용해 student 모델을 학습
- 라벨링 비용 절감, Teacher 모델이 라벨 없는 데이터를 효과적으로 활용해서 student 모델이 더 좋은 성능을 발휘하도록 도움.
연구 결과 및 해석
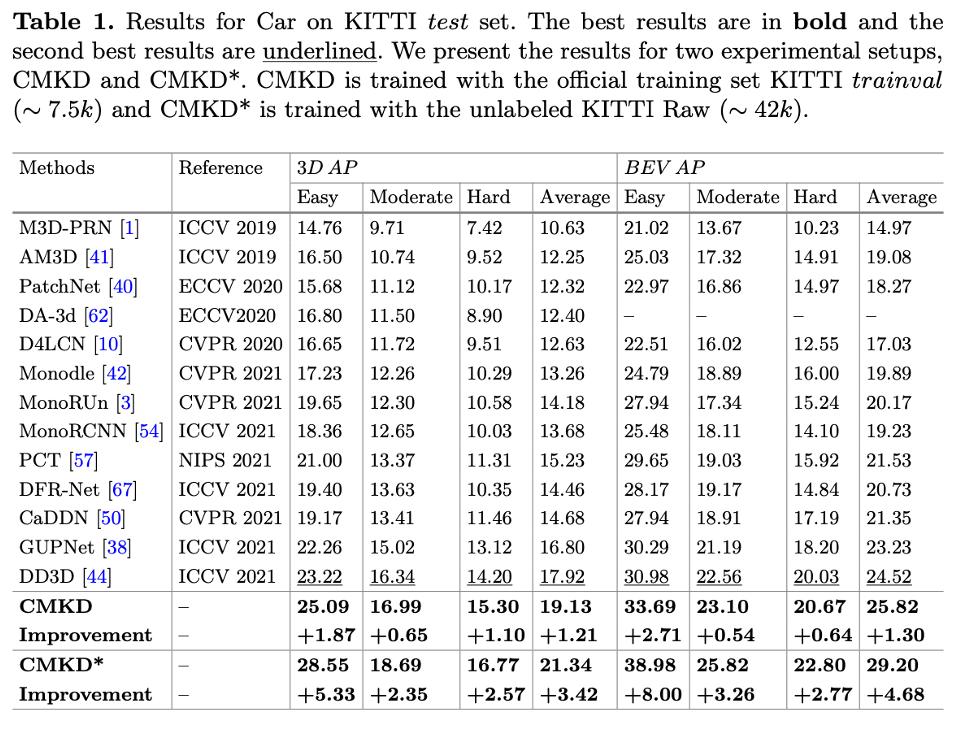
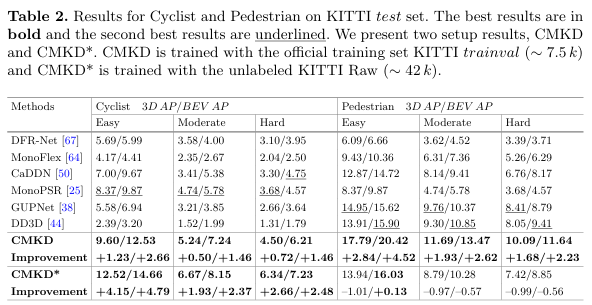
- CMKD: trained with the official training set KITTI trainval (~7.5k) for 80epochs
- CMKD*: trained with the unlabeled KITTI Raw (~42k) for 30 epochs

Ablation Study
-
Effectiveness of Both Distillation
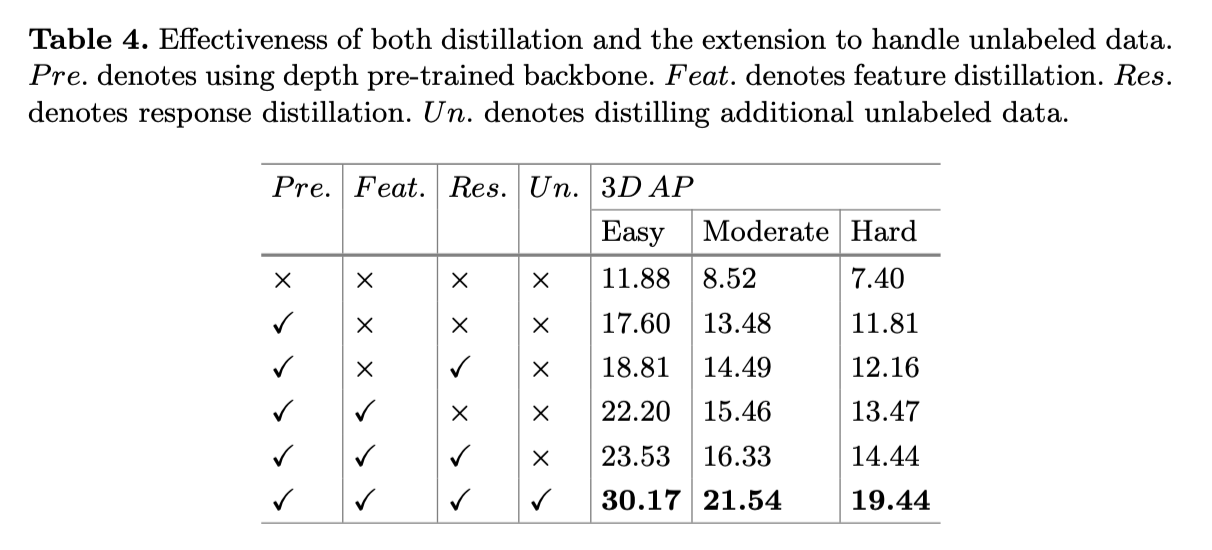
-
Effectiveness of Distilling Unlabeled Data
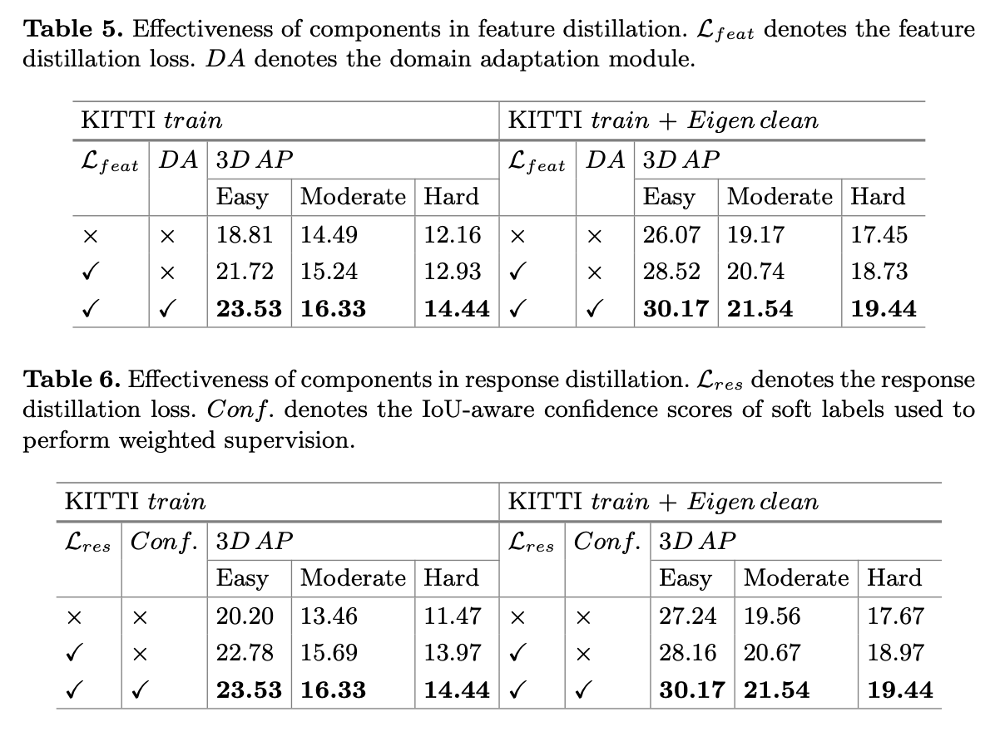
결론
- LiDAR 모달리티의 지식을 이미지 모달리티로 전이하여 단일 카메라 3D 탐지 정확도 크게 향상 라벨 없는 데이터를 활용한 semi-supervised learning framework로 확장하여 성능 향상 및 라벨링 비용 절감
- KITTI, Waymo 벤치마크에서 SOTA 달성
- CMKD는 단일 카메라 3D 탐지에 새로운 관점을 제시하며, 실제 환경에서 라벨 없는 데이터 활용 가능성을 입증
Note: LiDAR 데이터의 경우, 특히 라벨링하기 어려운데, 이런 라벨없는 대규모의 LiDAR 데이터셋을 활용해서 성능을 높이는 부분이 실제로도 도움이 많이 될 것 같음. BEV feature는 원래 LiDAR 데이터에서 사용되는 feature인데, image-based student 모델에서 depth distribution 정보를 바탕으로 입체적인 frustum grid의 feature를 만들고 BEV feature와 유사하게 만드는 과정이 새로웠음.