연구 배경
- 3D 장면 표현은 컴퓨터 비전에서 중요한 연구 분야이며, 최근 3D Gaussian Splatting(3DGS)이 실시간으로 고품질의 3D 렌더링을 가능하게 하는 기법으로 주목받고 있음.
- 기존 연구들은 3D 장면의 색상 및 형상을 잘 표현하지만, 시맨틱 정보(semantic information) 를 효과적으로 포함하지 못함.
- DGD는 3D Gaussian 표현을 기반으로 동적 3D 장면의 appearance, geometry, 그리고 semantics 를 함께 학습하는 방법을 제안함.
- 이를 통해 사용자가 클릭하거나 텍스트 프롬프트를 입력하는 방식으로 3D 객체를 직관적으로 선택 및 추적 할 수 있도록 함.
연구의 필요성
- 기존의 3D 표현 방식(ex. NeRF)은 실시간 렌더링이 어렵고, 시맨틱 정보 포함이 제한적 이었음.
- 기존 3DGS 연구들은 정적인(Static) 3D 장면에만 초점 을 맞추었으며, DGD는 이를 동적 장면으로 확장함.
- DGD는 2D 시맨틱 정보를 3D로 증류(distillation) 하여, 다양한 시맨틱 객체를 추적하고 편집할 수 있도록 만듦.
연구 방법론
3.1 Dynamic 3D Gaussians Representation
- 단일 카메라 비디오를 입력으로 받아 3D Gaussians 를 생성하고, 이를 최적화하여 시맨틱 정보를 포함한 동적 3D 표현을 학습함.
- 각 Gaussian은 다음과 같은 학습 가능한 변수 를 가짐:
- spatial 변수 (위치, 회전, 크기)
- Appearance 변수 (색상, 밀도)
- semantic feature vector (고차원 시맨틱 특징)
- 2D Foundation Model (ex. CLIP, DINO) 을 활용하여 2D에서 3D로 시맨틱 정보를 매핑 함.
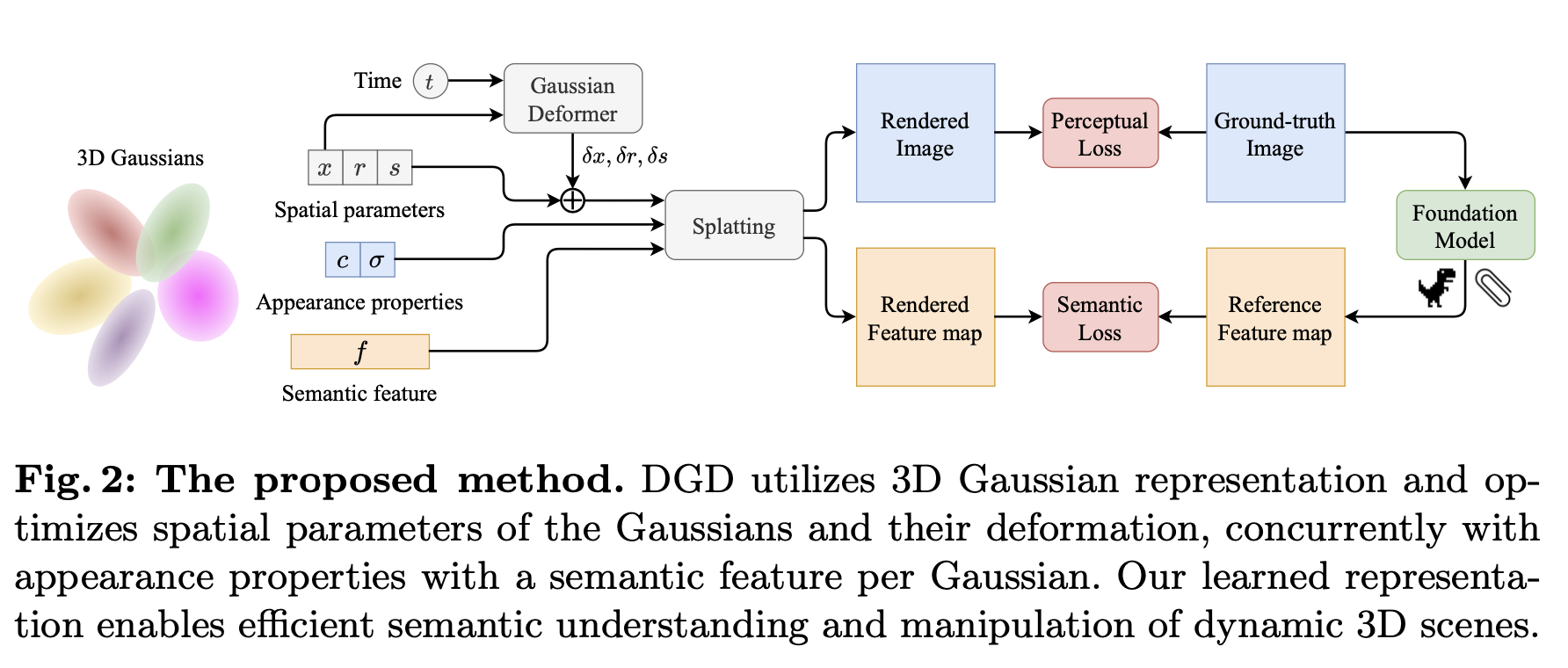
3.2 Dynamic Feature Distillation
- 각 3D Gaussian은 색상 정보뿐만 아니라 시맨틱 feature도 학습 함.
- Rasterization & Optimization:
- 3D Gaussians를 2D로 투영하여 색상과 시맨틱 feature를 최적화 함.
- 학습된 Gaussians는 색상, 공간 위치, 시맨틱 정보 를 반영하도록 업데이트됨.
3.3 3D Semantic Tracking
- 사용자가 텍스트 프롬프트 또는 3D 클릭 을 통해 특정 객체를 선택 하면, 해당 시맨틱 feature를 가진 Gaussians를 자동으로 필터링함.
- CLIP 기반의 텍스트-시맨틱 검색 을 사용하여 3D 객체를 탐색함.
- 3D 공간에서 유사한 feature를 가진 Gaussian을 선택하여 특정 객체를 추적함.

연구 결과 및 해석
4.1 3D Segmentation 및 Tracking 성능 비교
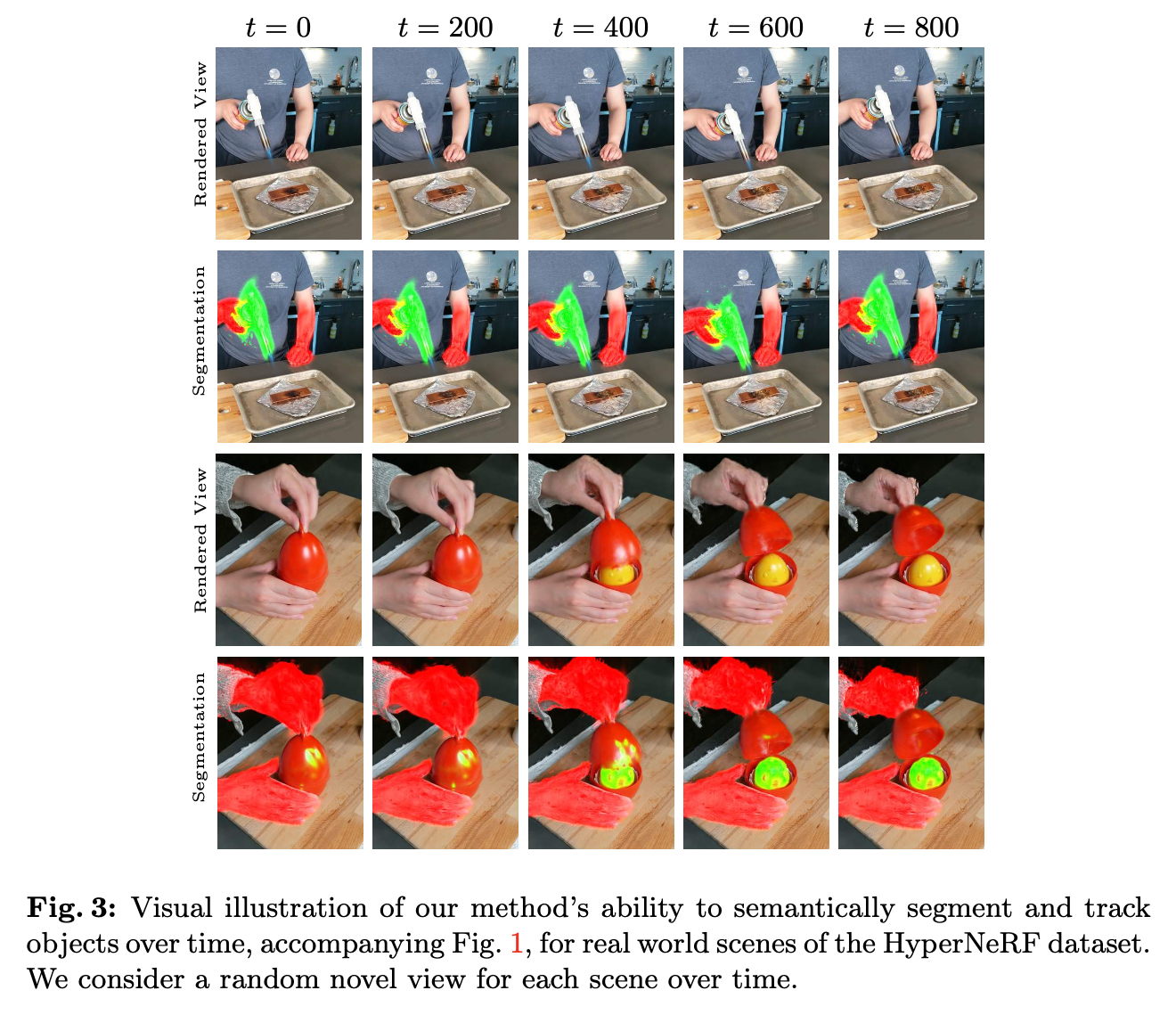
- HyperNeRF 및 D-NeRF 데이터셋 에서 단일 카메라 비디오만 사용하여 3D 객체 추적을 수행함.
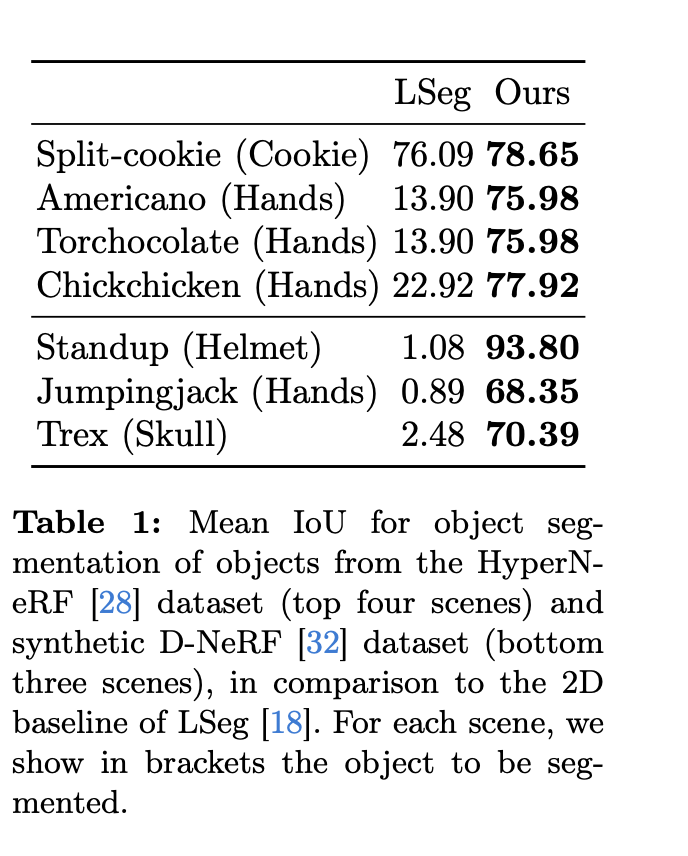
- LSeg(2D segmentation 모델) 및 기존 3DGS 기반 segmentation과 비교하여 높은 mIoU(Mean Intersection over Union) 성능 을 보임.
4.2 Perceptual User Study
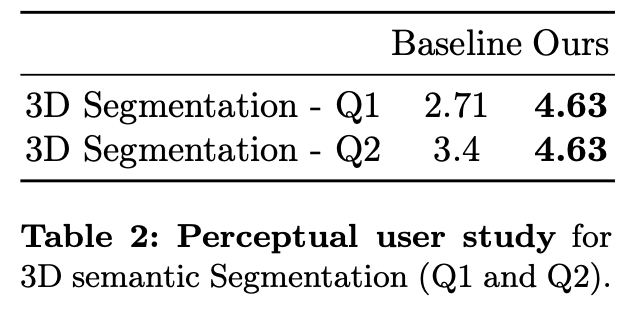
- 사용자가 객체가 얼마나 잘 분리되었는지(Q1) 와 다른 뷰에서 얼마나 일관성이 있는지(Q2) 를 평가하는 사용자 연구 수행.
- DGD가 기존 3DGS 기반 모델보다 더 직관적인 객체 추적 및 세분화 성능 을 보였음.
5. Semantic Editing (시맨틱 편집)
- 선택한 객체의 색상(texture), 기하학적 형상(geometry), 변형(deformation) 등의 속성을 편집 가능
- Stable Diffusion 기반의 SDS-Loss 를 활용하여 3D Gaussians의 색상을 텍스트 프롬프트로 변경 가능.
- ex. “cookie” 객체를 “strawberry” 로 변경하는 실험 수행

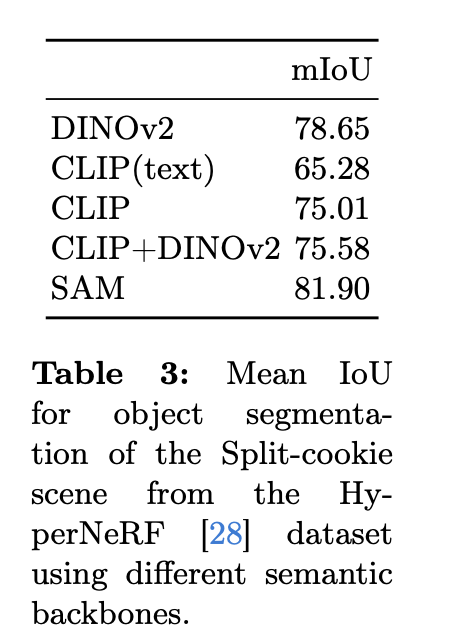
6. Ablation Study
- DINOv2, CLIP, SAM 등 다양한 백본(backbone) 모델을 실험
- SAM이 가장 높은 mIoU를 기록했지만, DINOv2와 CLIP 조합이 더 의미 있는 시맨틱 feature를 학습할 수 있었음.
6.2 Granularity Control
- Threshold(θ)를 조정하여 객체를 더 세부적으로 분리할 수 있음.
- ex. θ = 0.7 → 전체 손 추적 / θ = 0.9 → 손가락만 추적

7. 한계점 및 향후 연구 방향
- 낮은 프레임 속도의 비디오 를 입력으로 받을 경우 객체 추적이 어렵거나 부정확할 수 있음.
- 투명한 객체(ex. 유리) 를 정확하게 분리하는 것이 어려움.

8. 결론
- DGD는 3D Gaussian을 활용하여 동적 3D 장면의 appearance, geometry, semantics를 동시에 학습하는 새로운 방법
- 단일 카메라 비디오만으로 실시간 3D 객체 추적 및 편집 가능
- 향후 연구는 기하학적 편집 및 더 정교한 시맨틱 표현 확장 에 초점을 맞출 예정